
|
J. Wu, R. Antonova, A. Kan, M. Lepert, A. Zeng, S. Song, J. Bohg, S. Rusinkiewicz, T. Funkhouser |

|
F. Wei, T. Funkhouser, S. Rusinkiewicz |

|
J. Wu, X. Sun, A. Zeng, S. Song, S. Rusinkiewicz, T. Funkhouser |

|
K. Genova, X. Yin, A. Kundu, C. Pantofaru, F. Cole, A. Sud, B. Brewington, B. Shucker, T. Funkhouser |

|
J. Wu, X. Sun, A. Zeng, S. Song, S. Rusinkiewicz, T. Funkhouser |
|
F. Wei, E. Sizikova, A. Sud, S. Rusinkiewicz, T. Funkhouser |

|
K. Genova, F. Cole, A. Sud, A. Sarna, T. Funkhouser |

|
J. Wu, X. Sun, A. Zeng, S. Song, J. Lee, S. Rusinkiewicz, T. Funkhouser |
|
K. Genova, F. Cole, D. Vlasic, A. Sarna, W. T. Freeman, T. Funkhouser |

|
J. Huang, Y. Zhou, T. Funkhouser, L. Guibas |
|
M. Halber, Y. Shi, K. Xu, T. Funkhouser |

|
A. Zeng, S. Song, K. Yu, E. Donlon, F. R. Hogan, M. Bauza, D. Ma, O. Taylor, M. Liu, E. Romo, N. Fazeli, F. Alet, N. C. Dafle, R. Holladay, I. Morona, P. Q. Nair, D. Green, I. Taylor, W. Liu, T. Funkhouser, A. Rodriguez |

|

|
A. Zeng, S. Song, J. Lee, A. Rodriguez, T. Funkhouser |

|
|
J. Huang, H. Zhang, L. Yi, T. Funkhouser, M. Niessner, and L. Guibas |
|
S. Song and T. Funkhouser |

|
E. Balashova, A. H Bermano, V. G. Kim, S. DiVerdi, A. Hertzmann, T. Funkhouser |

|
E. Balashova, V. Singh, B. Teixeira, J. Wang, T. Chen, T. Funkhouser. |
|
Y. Zhang, S. Khamis, C. Rhemann, J. Valentin, A. Kowdle, V. Tankovich, M. Schoenberg, S. Izadi, T. Funkhouser, S. Fanello |
|
Y. Shi, K. Xu, M. Niessner, S. Rusinkiewicz, T. Funkhouser |

|
A. Zeng, S. Song, S. Welker, J. Lee, A. Rodriguez, T. Funkhouser |

|

|
S. Song, A. Zeng, A. X. Chang, M. Savva, S. Savarese, T. Funkhouser |

|

|
Y. Zhang, T. Funkhouser |

|
K. Genova, F. Cole, A. Maschinot, A. Sarna, D. Vlasic, W. Freeman |
|
B. Teixeira, V. Singh, K. Ma, B. Tamersoy, T. Chen, Y. Wu, E. Balashova, D. Comaniciu |

|
M. Savva, A. X. Chang, A. Dosovitskiy, T. Funkhouser, V. Koltun |

|

|
A. Zeng, S. Song, K.T. Yu, E. Donlon, F.R. Hogan, M. Bauza, D. Ma, O. Taylor, M. Liu, E. Romo, N. Fazeli, F. Alet, N.C. Dafle, R. Holladay, I. Morona, P.Q. Nair, D. Green, I. Taylor, W. Liu, T. Funkhouser, and A. Rodriguez |
|
|
Y. Zhang, M. Bai, P. Kohli, S. Izadi, and J. Xiao |

|
|
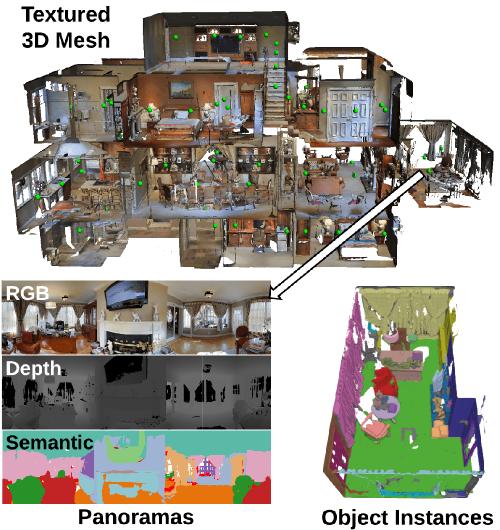
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y. Zhang |
|
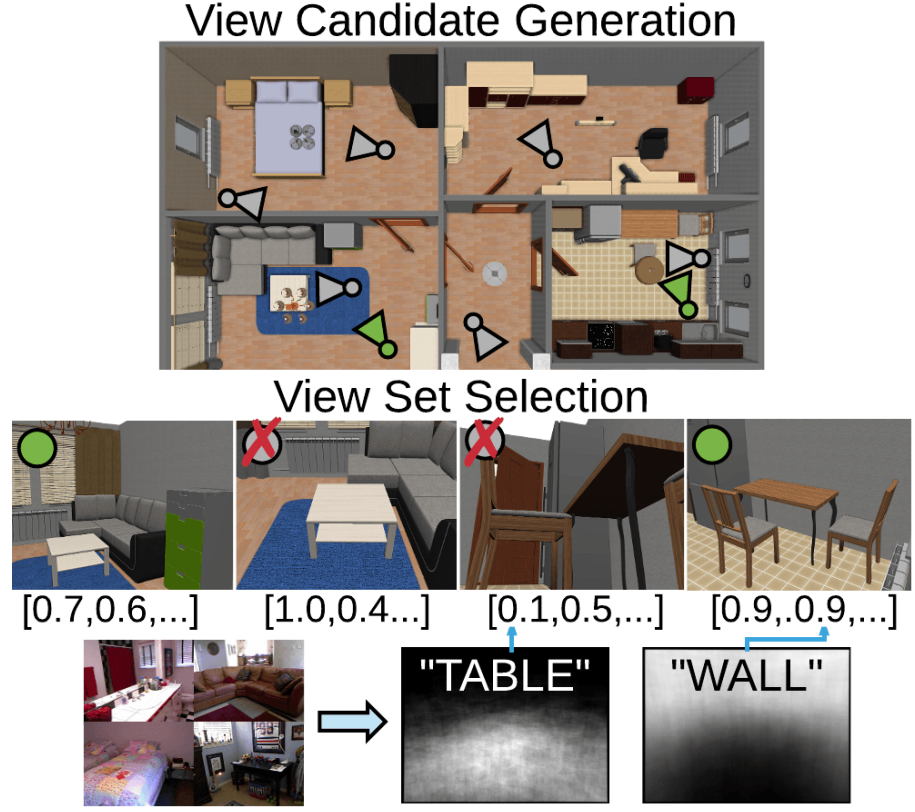
K. Genova, M. Savva, A. X. Chang, T. Funkhouser |

|
J. Liu, F. Yu, and T. Funkhouser |

|
S. Song, F.Yu, A. Zeng, A. Chang, M. Savva, and T. Funkhouser |

|
|
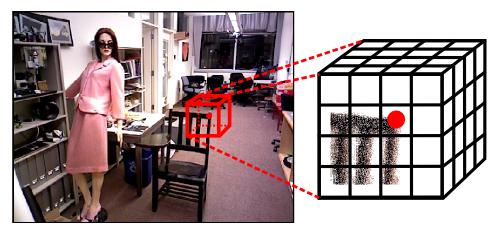
A. Zeng, S. Song, M. Nießner, M. Fisher, J. Xiao, and T. Funkhouser |

|

|
H. Xu, Y. Gao, F. Yu, and T. Darrell |

|
A. Dai, A. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner |

|
M. Halber and T. Funkhouser |
|
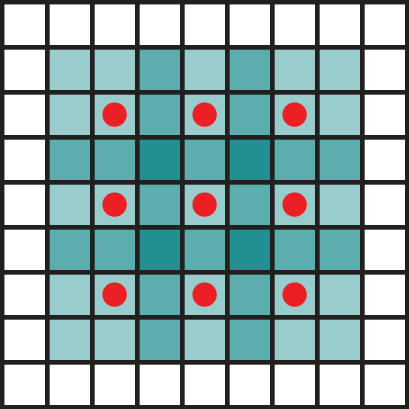
Y. Zhang*, S. Song*, E. Yumer, M. Savva, J. Lee, H. Jin, and T. Funkhouser |
|
F. Yu, V. Koltun, and T. Funkhouser |

|
P. Sangkloy, J. Lu, C. Fang, F. Yu, and J. Hays |

|
A. Zeng, K.T. Yu, S. Song, D. Suo, E. Walker Jr., A. Rodriguez, and J. Xiao |

|
|
A. Seff and J. Xiao. |

|
S. Song, and J. Xiao |

|
|
F. Yu and V. Koltun |

|
C. Chen, A. Seff, A. Kornhauser and J. Xiao. |

|

A. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, J. Xiao, L. Yi, and F. Yu.
ShapeNet: An Information-Rich 3D Model Repository
arXiv:1512.03012 [cs.CV] 9 Dec 2015
Paper ·
ShapeNet dataset

|
S. Song, L. Zhang, and J. Xiao. |

|

|
Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang and J. Xiao |

|
|
S. Song, S. Lichtenberg, and J. Xiao |

|

F. Yu, A. Seff, Y. Zhang, S. Song, T. Funkhouser and J. Xiao.
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
arXiv:1506.03365 [cs.CV] 10 Jun 2015
Paper ·
LSUN dataset

|
F. Yu, J. Xiao, and T. Funkhouser |

|
|
P. Xu, K. A. Ehinger, Y. Zhang, A. Finkelstein, S. R. Kulkarni, and J. Xiao. |

|
|
S. Song and J. Xiao |

|

|
Y. Zhang, S. Song, P. Tan, and J. Xiao |

|

S. Song and J. Xiao
Tracking Revisited using RGBD Camera: Unified Benchmark and Baselines
Proceedings of 14th IEEE International Conference on Computer Vision (ICCV 2013)
Paper ·
Project Webpage, Data, Source Code and Evaluation Server ·
Poster · Spotlight · Talk Slides · Video

J. Xiao, A. Owens and A. Torralba
SUN3D: A Database of Big Spaces Reconstructed using SfM and Object Labels
Proceedings of 14th IEEE International Conference on Computer Vision (ICCV 2013)
Paper ·
Project Webpage, Data and Source Code ·
Poster · Spotlight · Talk Slides
· Video (HighRes, YouTube)

B. Zhou, A. Lapedriza, J. Xiao, A. Torralba, and A. Oliva
Learning Deep Features for Scene Recognition using Places Database
Advances in Neural Information Processing Systems 27 (NIPS 2014)
Paper ·
Project Webpage, Data, and Demo

J. Xiao, K. A. Ehinger, J. Hays, A. Torralba, and A. Oliva
SUN Database: Exploring a Large Collection of Scene Categories
International Journal of Computer Vision (IJCV)
Paper
·
Database Webpage
·
Scene Classification Benchmark Webpage
J. Xiao, K. A. Ehinger, A. Oliva and A. Torralba
Recognizing Scene Viewpoint using Panoramic Place Representation
Proceedings of 25th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2012)
Paper ·
Project Webpage (Dataset and Source Code)